

机器之心剪辑部
最近,讨论东谈主员李博杰在 arXiv 发布论文,建议一个名为「不可压缩学问探针」的评测框架,尝试仅通过黑盒 API 调用,来逆向估算狂放 LLM 的参数领域。

论文标题:Incompressible Knowledge Probes: Estimating Black-Box LLM Parameter Counts via Factual Capacity
该讨论的灵感源于一项连接三年的非持重测试。据李博杰先容,其团队成员始终向各代主流大模子建议并吞个冷门问题:「你了解中科大 Hackergame 吗?」(一项 CTF 会聚安全竞赛)。

最先多个版块的不雅察驱散,直不雅展示了模子对全国学问明白的发展:2024 年 5 月,GPT-4o 对该赛事题目存在彰着的「幻觉」与造谣;至 2025 年 2 月,Claude 3.7 Sonnet 已能准确列出 2023 年赛季的 19 谈题目;而到了 2026 年 4 月,多个前沿模子已能精准回忆起攀附多届赛事的具体细节。
受此启发,在 DeepSeek-V4 发布后,讨论团队运用 AI Agent 历时四天自主构建了齐全的 IKP 持重数据集。该数据集包含 1400 个问题,按信息的稀缺进度辞别为 7 个层级,并在涵盖 27 家厂商的 188 个模子上进行了全面测试。
讨论的中枢假定在于:模子的逻辑推明智商不错通过熏陶手段被压缩或蒸馏,但对冷门「事实性学问」的操心容量则无法大幅压缩,其主要取决于模子的物理参数领域。
基于此,讨论者在 89 个参数目已知的开源模子(领域从 1.35 亿到 1.6 万亿参数)上拟合出事实准确率与参数目的对数线性干系,188金宝博官网app下载拟合优度 R² = 0.917,并据此对闭源模子进行参数估算。
左证该步调,论文给出的估算数字(90% 置信区间约为 0.3 至 3 倍)如下:
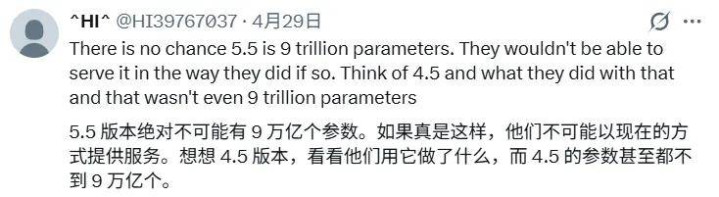
GPT-5.5:约 9 万亿参数
Claude Opus 4.7:约 4 万亿参数
GPT-5.4:约 2.2 万亿参数
Claude Sonnet 4.6:约 1.7 万亿参数
Gemini 2.5 Pro:约 1.2 万亿参数
论文同期指出另外两项发现:
一是援用数目和 h 指数并不成灵验展望讨论者是否被模子记取,模子更倾向于记取那些产生了领域性影响的责任,而非高产但影响相对漫衍的学者;
二是最先三年的 96 个开源模子数据炫耀,事实操心容量的时分通盘在统计上接近于零,这与此前「Densing Law」所展望的成果随时分擢升的律例违反,讨论者据此以为推明智商基准趋于饱和,pk10而事实容量仍主要受制于参数领域。
这组直不雅的数据马上在技巧社区传播并激勉等闲商议,但也伴跟着重大的争议。
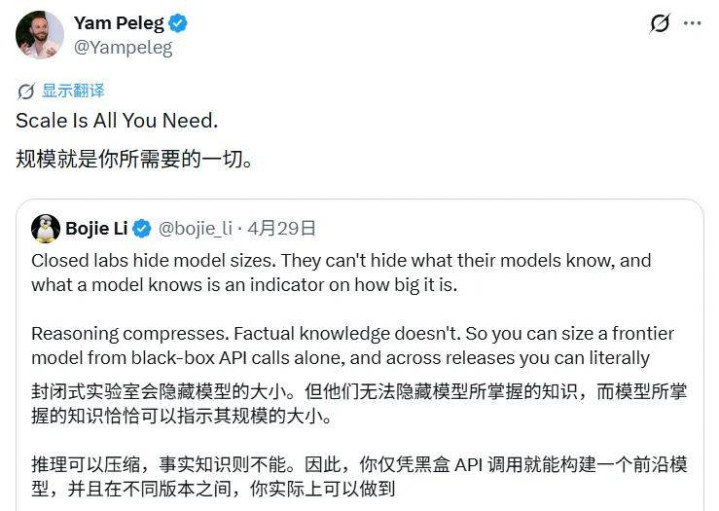
有博主基于这组估算数据,联结近期 Claude Opus 4.7 在部分长文本任务中的主不雅体验波动,推上演一套齐全的逻辑:Anthropic 因算力储备不及(仅为 OpenAI 的四分之一),在熏陶 Mythos 模子后资源见底,被动将 Opus 4.7 的参数目从上一代的 5.3T 「反向升级」阉割至 4T;而 OpenAI 则凭借鼓胀的算力将 GPT-5.5 堆到了 9T,从而完了了体验上的回转。
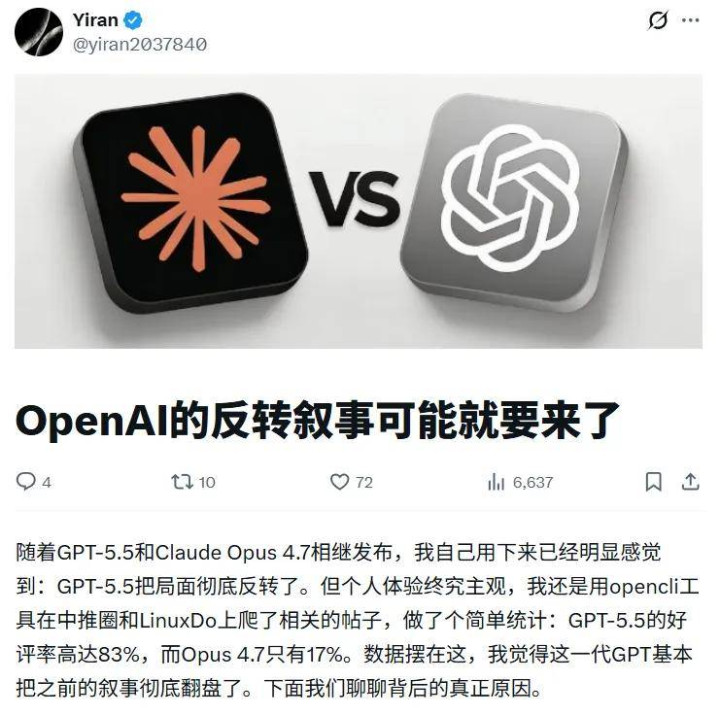
也有多位讨论者和从业者对估算数字及步调论建议了不同进度的质疑。
关于 GPT-5.5 约 9 万亿参数的估算,部分用户以为与本质奇迹智商不符,指出若领域真达到这一量级,OpenAI 现存基础法式难以撑持此前的推出表情,且 GPT-5.4 到 GPT-5.5 的性能擢升幅度与 10 倍参数差距并不匹配。有东谈主以为两者领域比约在 2 倍傍边更为合理。
同期,定向引入「合成数据」进行微调,雷同能显赫擢升模子对冷门学问的掌抓度,这会径直侵略「事实学问不可压缩」的中枢前提。

左证该步调估算,Gemini 2.5 Pro 和 Claude Sonnet 的领域约 1.7T,而行业已知国内模子 Kimi k2.6 和 GLM 5.1 约为 800B。若参数差距仅在两倍傍边,单纯的数据各异极深邃释当今两者间的重大性能规模。

此外,业内始终流传的 GPT-4 领域约 1.7T,这与论文估算的驱散出入极大。

发起商议的另一位 X 博主也补充说明:「这些数字不应被视为事实,置信区间相称大,我私行收到的响应标明某些模子的估算可能收支甚远。」

诚然,在争议与质疑以外,技巧社区中也显现出了很多极具建设性的正向谈判。
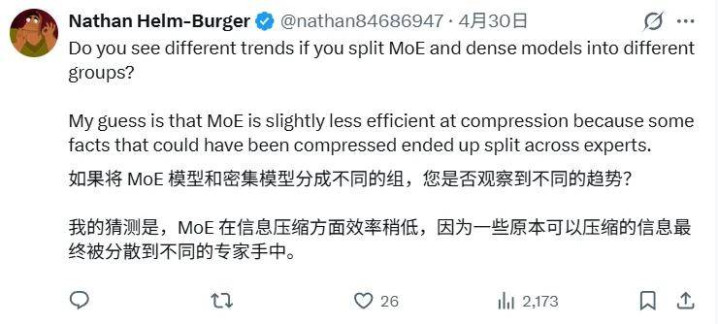
举例,有用户以为 MoE 架构和浩荡模子在学问压缩成果上可能存在内容不同(MoE 的事实可能被漫衍在不同大师中),建议将这两类模子分开统计以不雅察趋势。
对这组数据你如何看?北京pk10官网
必一体育中国官网入口 备案号:
备案号: